漫画分析
Saber Translator 的漫画分析系统灵感来自 谷歌NotebookLM,并针对漫画这一特殊场景做了专门优化。借助 RAG 知识库架构与多层摘要流程,您可以把整部漫画整理成可检索、可提问、可继续创作的分析结果。
功能概述
漫画分析当前提供以下能力:
- 内容理解:识别角色、场景、对话、情感
- 剧情分析:提取故事线、关键事件和章节脉络
- 智能问答:基于分析结果回答问题
- 时间线整理:按事件顺序重建剧情发展
- 数据导出:生成结构化分析报告
- 后续联动:为漫画续写和角色工坊提供上游数据
页面结构
分析页通常由两部分组成:
左侧区域
- 选择要分析的书籍
- 启动、暂停、继续或取消分析任务
- 查看分析进度
- 浏览章节和页面导航树
主内容标签
- 概览:查看故事概要、角色信息和模板内容
- 智能问答:围绕剧情细节提问
- 时间线:查看关键事件顺序
- 续写:进入基于分析结果的续写流程
- 角色工坊:进入角色资料独立工作台的入口
提示
角色工坊的入口位于分析页中,但打开后会进入独立工作台,并不是一直停留在当前分析面板里。
分析架构
架构预设
系统提供五种分析架构预设,适应不同篇幅和类型的漫画:
| 预设 | 层级结构 | 适用场景 |
|---|---|---|
| 简洁模式 | 批量分析 → 全书总结 | 短篇漫画(<50 页),快速分析 |
| 标准模式 | 批量分析 → 段落总结 → 全书总结 | 中篇漫画(50-200 页),平衡质量和成本 |
| 章节模式 | 批量分析 → 章节总结 → 全书总结 | 有明确章节划分的长篇漫画 |
| 完整模式 | 批量分析 → 小总结 → 章节总结 → 全书总结 | 长篇漫画(>200 页),追求更完整结果 |
| 自定义模式 | 完全自定义层级架构 | 特殊需求,灵活配置 |
层级说明
text
批量分析(基础层)
↓
段落 / 章节总结(中间层,可多级)
↓
全书概述(顶层)| 层级 | 说明 |
|---|---|
| 批量分析 | 每 N 页为一批,由 VLM 分析图片内容 |
| 段落总结 | 汇总多个批次,整理剧情和关键事件 |
| 章节总结 | 按章节汇总内容 |
| 全书概述 | 整合整本漫画,生成全局概要 |
开始分析
前置条件
- 书籍已添加到书架系统
- 章节已上传图片
- 已配置分析所需模型
配置模型
在设置中配置分析模型:
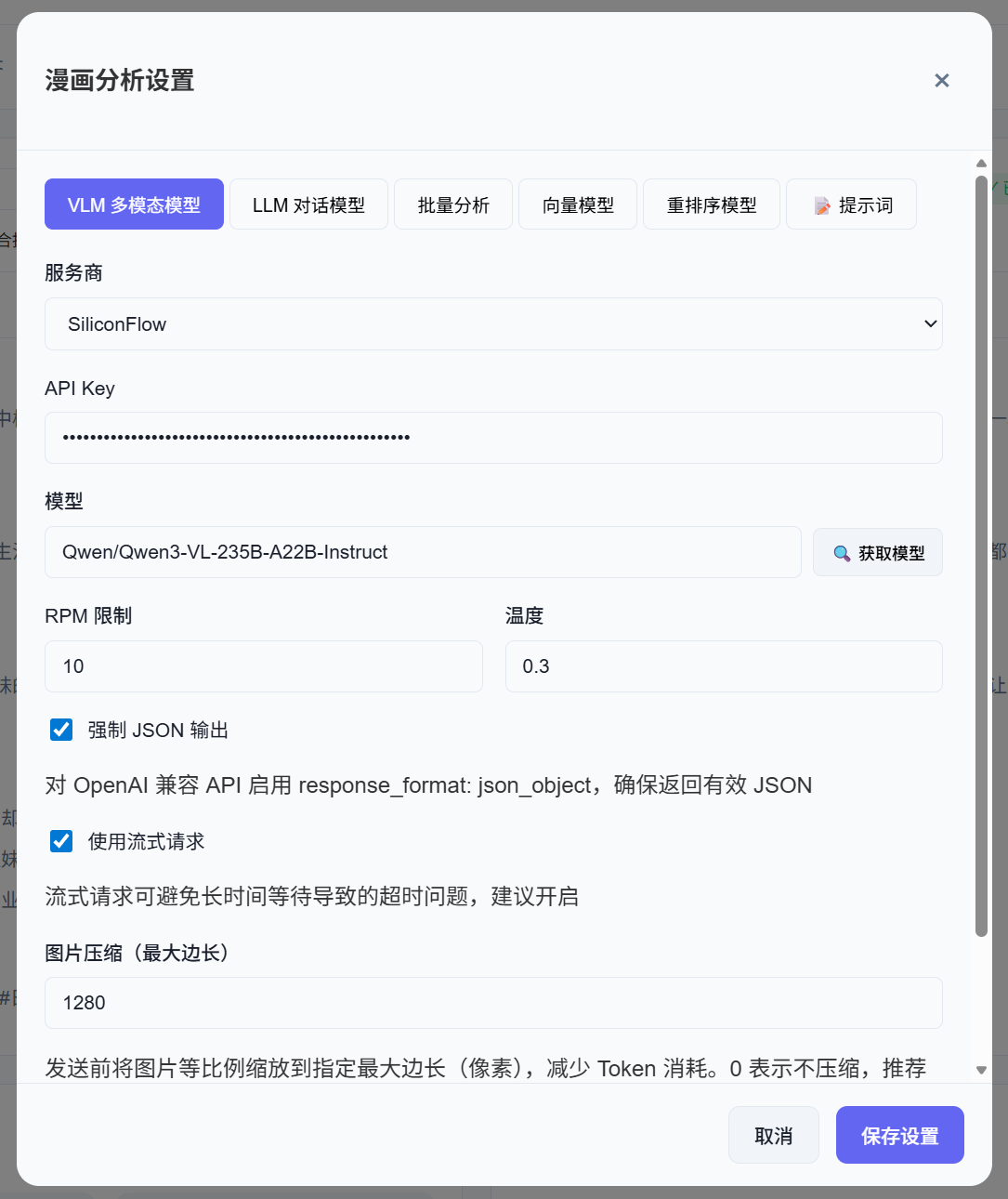
VLM 多模态模型(必需)
用于批量分析,需要支持图片输入(详见 模型类型说明):
| 参数 | 说明 |
|---|---|
| 服务商 | 选择 VLM 服务商 |
| API Key | 填写 API 密钥 |
| 模型 | 选择多模态模型 |
| RPM 限制 | 每分钟请求数限制 |
| 强制 JSON | 提高结构化输出稳定性 |
| 流式请求 | 减少长请求超时风险 |
| 图片压缩 | 控制分析时图片大小 |
LLM 对话模型(可选)
用于总结和智能问答:
- 可与 VLM 使用相同配置
- 也可单独配置更适合文本任务的模型
Embedding 向量模型(智能问答必需)
用于构建知识库和语义检索:
- 选择支持的服务商和向量模型
- 未配置时,智能问答能力会受限
Reranker 重排序模型(可选)
用于优化检索结果:
- 提高问答精度
- 非必需,但能改善复杂问题的相关性
生图模型(续写建议提前配置)
如果您后续还准备使用漫画续写,建议在分析设置中一并配置好生图模型,这样续写阶段会更顺畅。
启动分析

- 进入漫画分析页面
- 选择要分析的书籍
- 选择分析模式
- 点击“开始分析”
分析模式
全书分析
分析整本书籍的所有页面:
- 适用于首次分析
- 结果最完整
- 耗时通常也最长
增量分析
只分析新增或未分析的页面:
- 适合连载更新
- 能避免重复分析旧页面
章节分析
分析指定章节:
- 适合只关注部分剧情
- 可选择一个或多个章节
页面分析
分析指定页面范围:
- 适合精细控制范围
- 适合补分析或局部重跑
批量分析参数
在设置 → 批量分析中配置:
每批次分析页数
控制每次发送给 VLM 的图片数量:
- 推荐值:3-5 张
- 较小值(1-2):更稳定
- 较大值(5-10):更高效,但超时风险更高
注意
图片越多,上下文越连贯,但也会增加 Token 消耗和超时风险。
上文参考批次数
每批分析时参考前几批的结果作为上下文:
- 0:不参考前文,每批独立分析
- 1-5:参考前 N 批,增强连贯性
分析架构预设
根据漫画篇幅选择合适的架构:
| 预设 | 说明 |
|---|---|
| 简洁模式 | 批量分析 → 全书总结(适合短篇) |
| 标准模式 | 批量分析 → 段落总结 → 全书总结(推荐) |
| 章节模式 | 批量分析 → 章节总结 → 全书总结(有章节划分) |
| 完整模式 | 批量分析 → 小总结 → 章节总结 → 全书总结(长篇) |
| 自定义模式 | 完全自定义层级架构(高级用户) |
分析控制
任务管理
| 操作 | 说明 |
|---|---|
| 暂停 | 暂停当前分析任务 |
| 继续 | 恢复已暂停的任务 |
| 取消 | 取消分析任务 |
进度查看
分析进行中可查看:
- 当前进度(已分析 / 总页数)
- 当前批次和总批次数
- 实时状态更新
查看结果
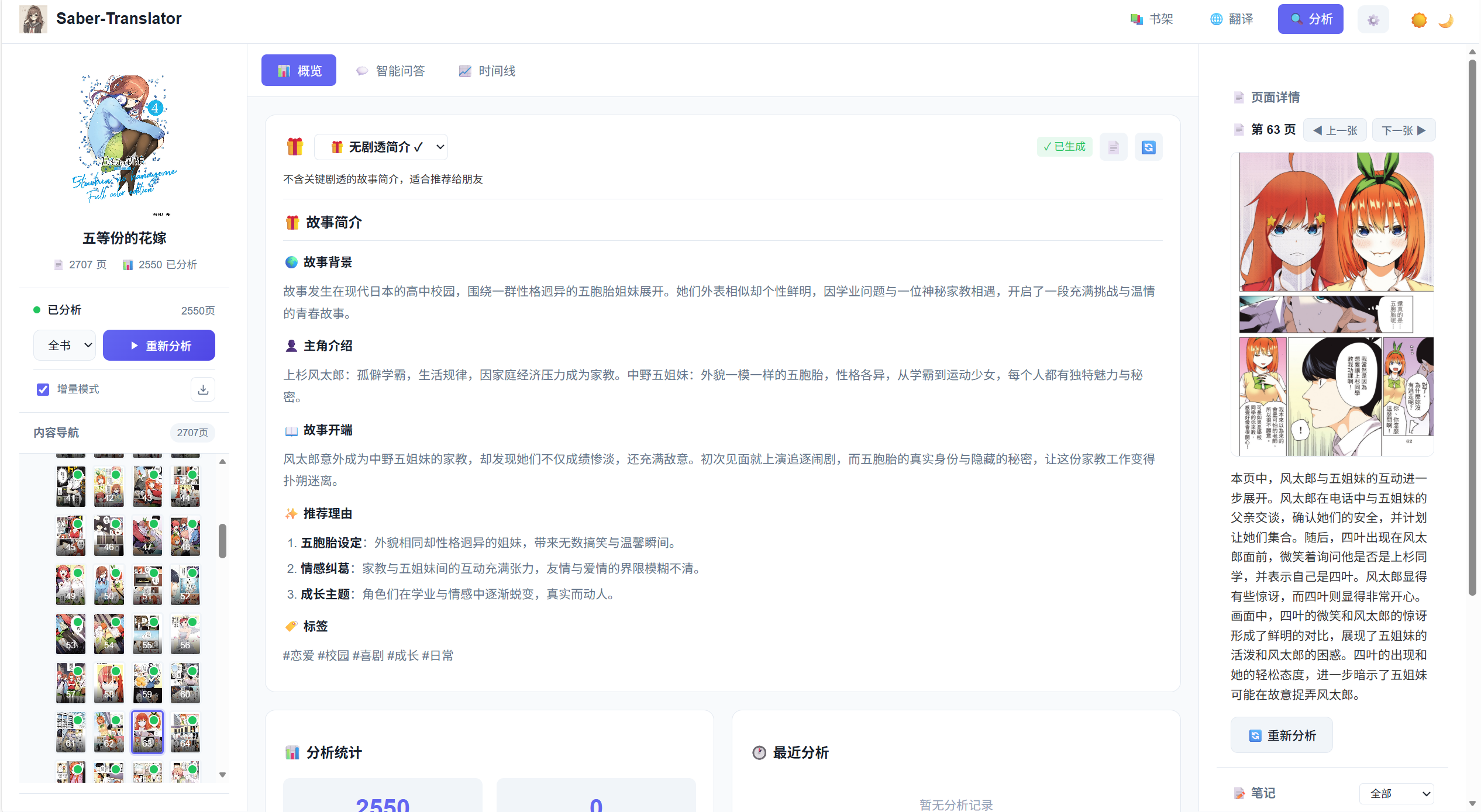
故事概述
全书分析完成后,会在概览区域生成整体概要:
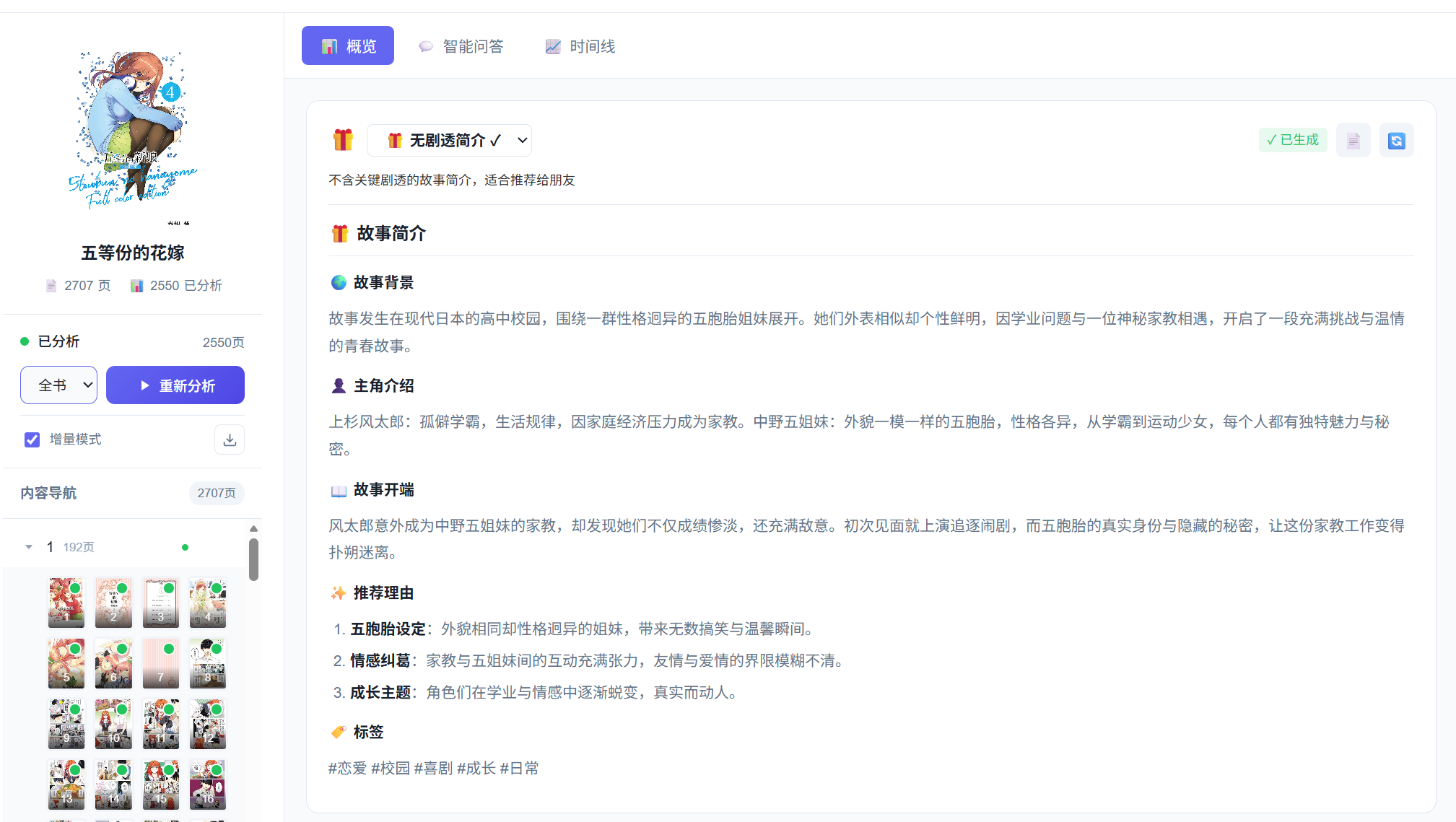
- 故事简介
- 主要角色
- 核心主题
- 剧情走向
页面详情
单页的详细分析通常包含:
- 场景描述
- 角色识别
- 对话内容
- 情感分析
- 画面构图
剧情时间线
按时间顺序排列的关键事件:
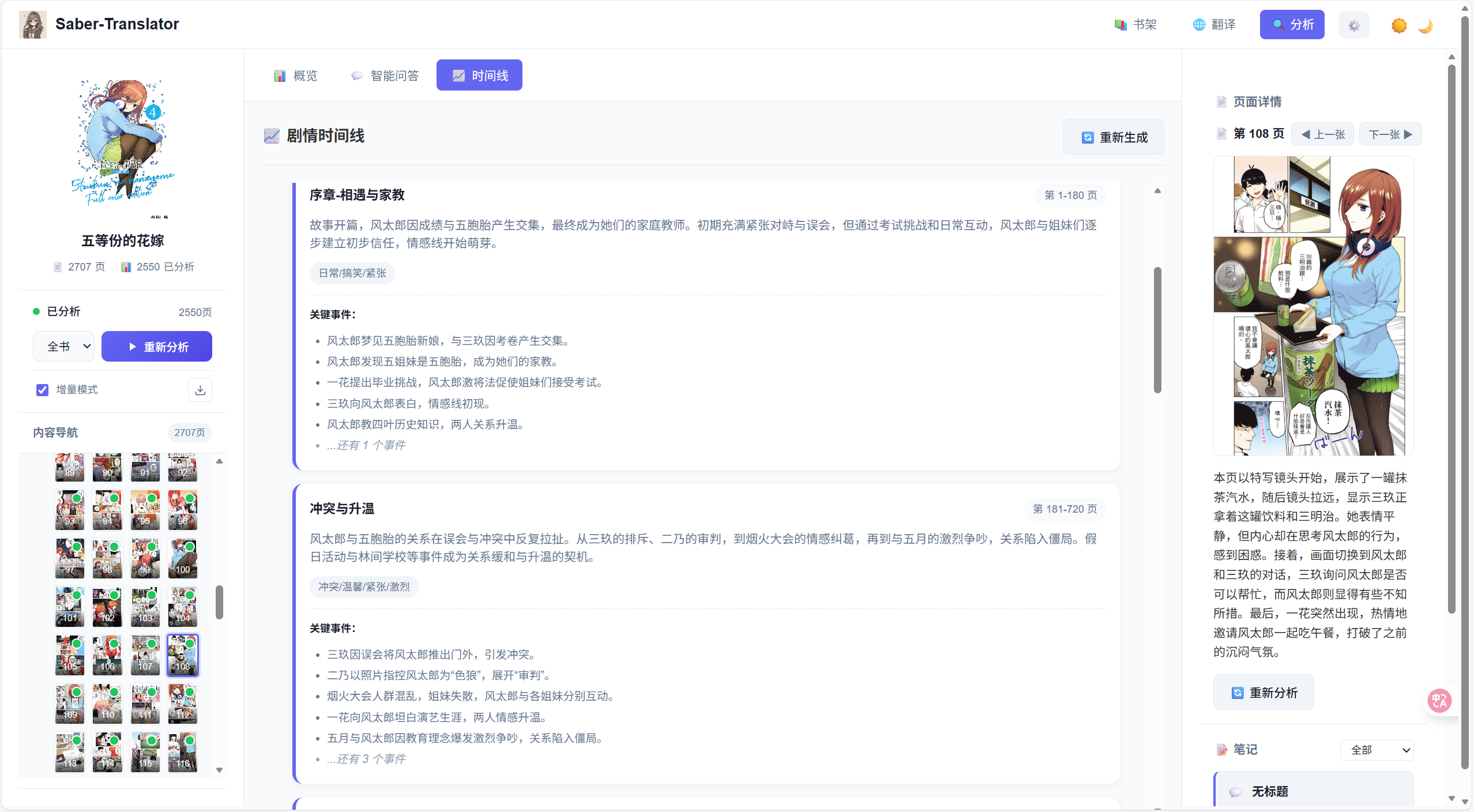
- 简单模式:事件列表
- 增强模式:AI 整合的剧情弧与角色行动线
智能问答
基本使用
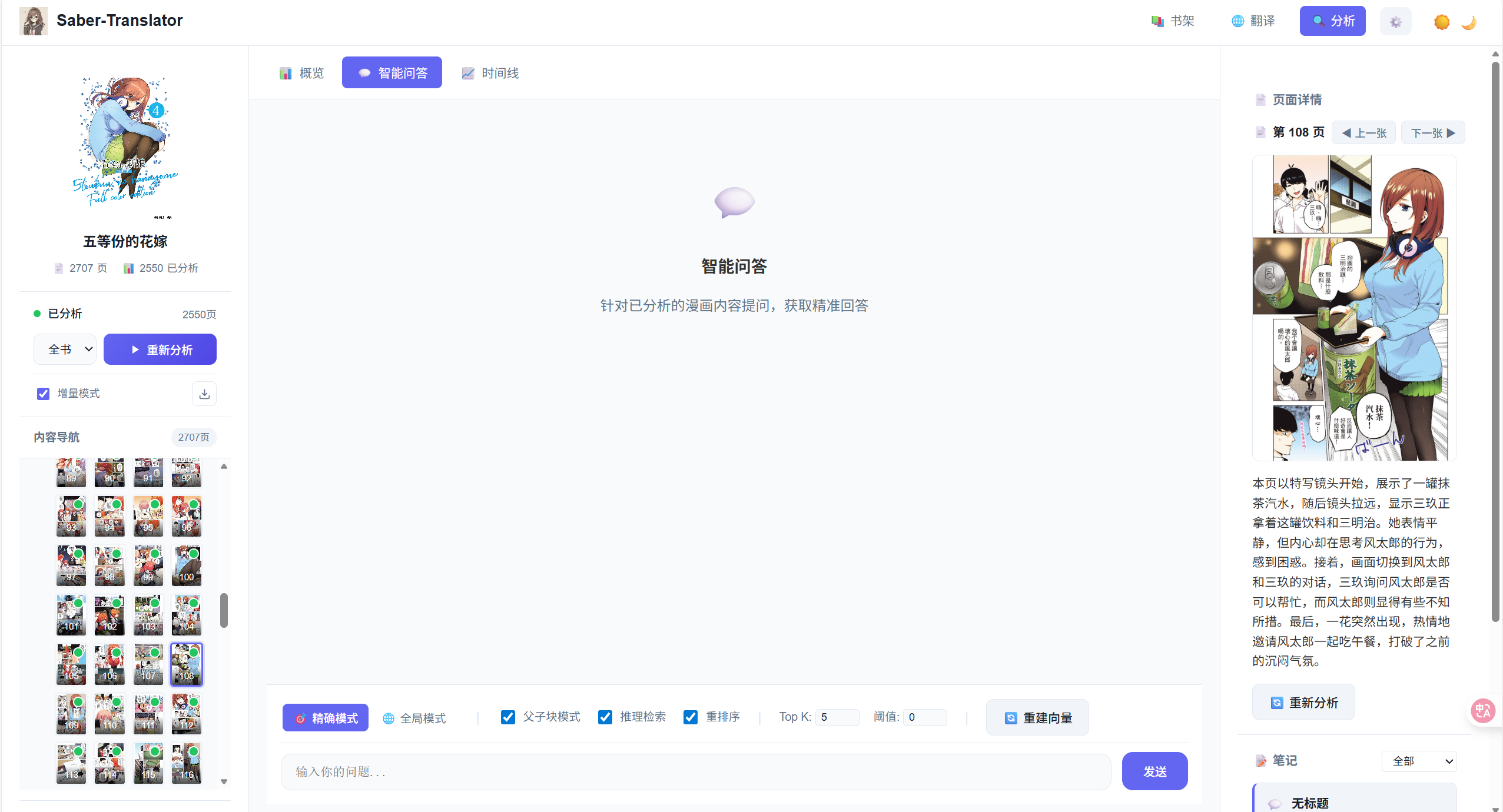
- 在问答区输入问题
- 点击发送或按 Enter
- 查看 AI 回答和引用来源
问答模式
精确模式(默认):
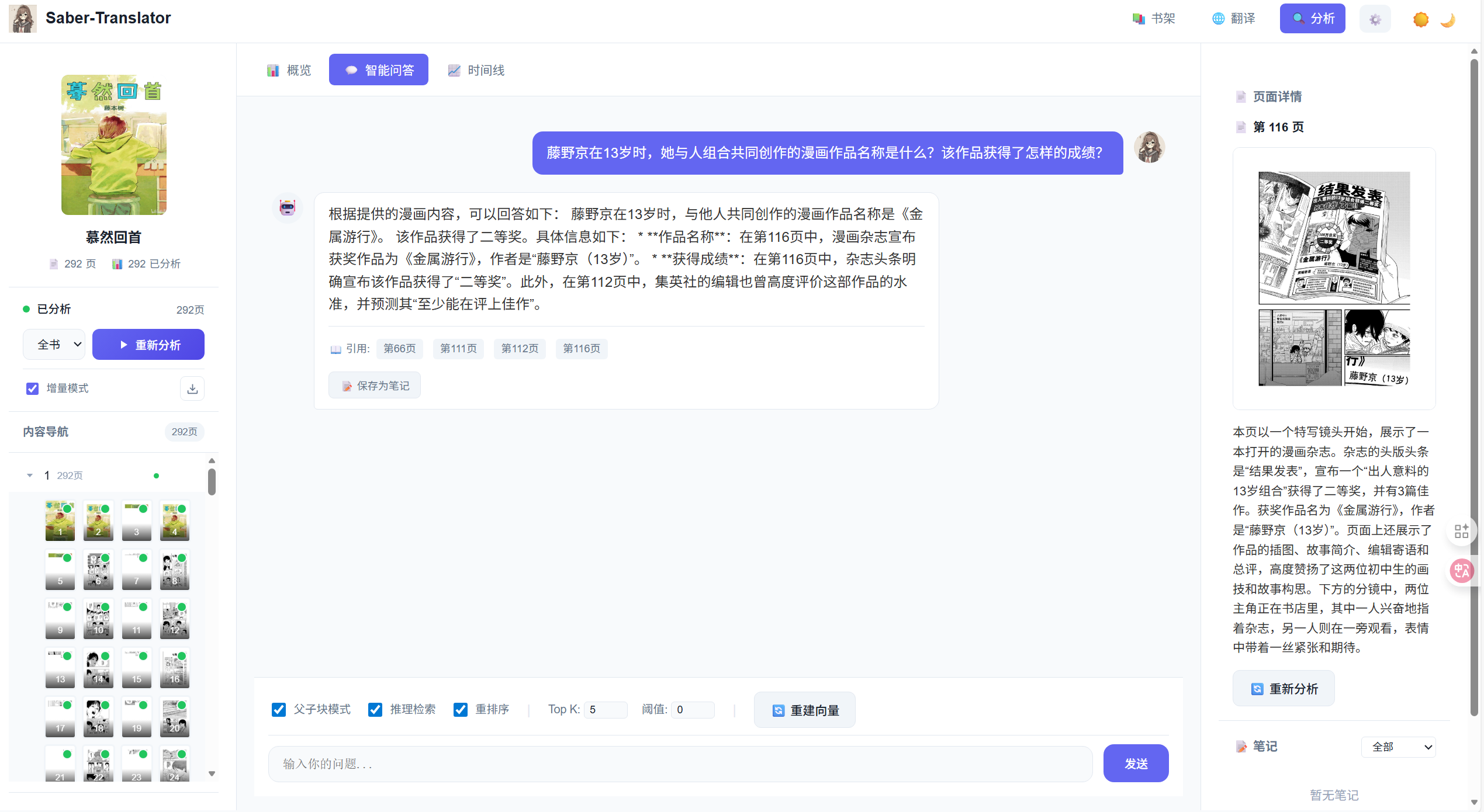
- 使用 RAG 检索相关内容
- 适合具体问题,例如“第 15 页发生了什么?”
- 答案通常带有明确引用来源
全局模式:
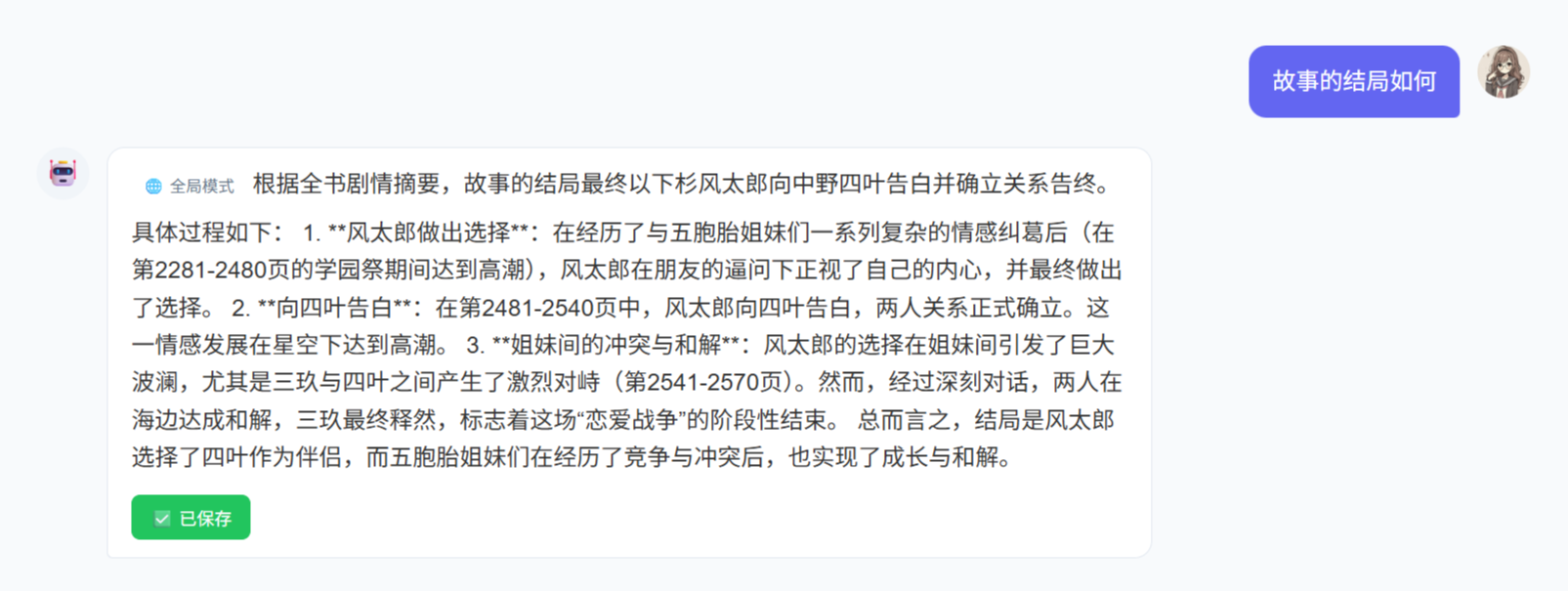
- 使用全书摘要作为上下文
- 适合总结性问题,例如“这个故事的主题是什么?”
- 需要先有足够完整的全书概述
高级选项
| 选项 | 说明 |
|---|---|
| 父子块模式 | 返回匹配页面所属批次的完整上下文 |
| 推理检索 | 拆分复杂问题后再综合回答 |
| 使用重排序 | 启用 Reranker 进行二次精排 |
| Top K | 返回的最大结果数 |
| 相关性阈值 | 过滤低相关内容 |
| 重建向量 | 删除现有索引并重新构建 |
数据导出
导出格式
JSON 格式:
- 结构化数据
- 便于程序处理
- 包含完整分析内容
Markdown 格式:
- 人类可读
- 便于分享和阅读
- 适合导出为笔记
导出内容
可选择导出的内容:
- 故事概述
- 章节分析
- 页面详情
- 时间线
- 角色档案
模板系统
概述模板
系统提供多种概述生成模板:
| 模板 | 说明 |
|---|---|
| 无剧透简介 | 不包含剧透的故事介绍,适合推荐 |
| 故事概要 | 完整剧情回顾,包含所有剧透 |
| 前情回顾 | 总结已发生事件,适合续读前快速回忆 |
| 角色图鉴 | 梳理角色信息与关系 |
| 世界观设定 | 汇总背景与设定 |
| 名场面盘点 | 汇总精彩片段与高光场面 |
| 阅读笔记 | 生成结构化阅读记录 |
生成和管理
生成概述:
- 在概览页面选择模板类型
- 点击“生成”按钮
- AI 基于分析数据生成内容
重新生成:
- 点击“重新生成”按钮
- 使用当前分析数据再生成一版
模板状态:
- 显示是否已生成
- 显示最后生成时间
与续写和角色工坊联动
漫画续写
漫画续写位于分析页标签中,适合在以下前提下使用:
- 已有较完整的分析结果
- 角色关系和剧情脉络已经梳理清楚
- 已配置续写所需的生图模型
角色工坊
角色工坊同样从分析页进入,但会打开独立工作台。它更适合:
- 把角色摘要整理成长期可维护资料
- 为聊天、续写、世界书等用途准备结构化角色文档
- 做角色设定校验、导入导出和预览
向量存储
功能说明
分析结果会存储到向量数据库,用于:
- 语义检索
- 智能问答
- 相似内容查找
重建索引
如果问答效果不佳,可重建向量索引:
- 点击“重建向量索引”
- 等待索引完成
- 再重新提问或测试结果
最佳实践
分析流程建议
text
1. 先进行全书分析或增量分析
2. 等待核心结果生成完成
3. 先看概览,确认整体理解是否正常
4. 再看页面详情和时间线
5. 然后使用智能问答深挖细节
6. 如有需要,再进入续写或角色工坊成本控制
分析功能通常比普通翻译更重,建议:
- 先用少量页面测试配置
- 确认 VLM 和问答链路可用后再分析整本
- 连载更新时优先使用增量分析
- 把高成本模型留给真正需要的任务
常见问题
分析失败
可能原因:
- API 配置错误
- 网络连接问题
- 模型不支持图片输入
解决方法:
- 检查 API Key 是否有效
- 确认使用的是视觉模型
- 查看日志定位出错阶段
问答无结果
可能原因:
- 尚未完成分析
- 向量索引未建立
- 问题与内容相关性过低
解决方法:
- 确认分析已完成
- 重建向量索引
- 调低相关性阈值或换一种问法