模型类型说明
文本模型 vs 多模态模型
软件的翻译功能会用到的模型有文本模型和多模态模型。二者的区别和使用场景如下
文本模型
特点:只能处理文字输入
适用场景:普通翻译模式。即软件的翻译当前图片与翻译所有图片这两个功能。

代表模型:deepseek-v3.2
多模态模型
特点:可以同时理解图片和文字,可以理解为带有视觉读图能力的文本模型
适用场景:高质量翻译、AI 视觉 OCR、AI 校对、漫画分析

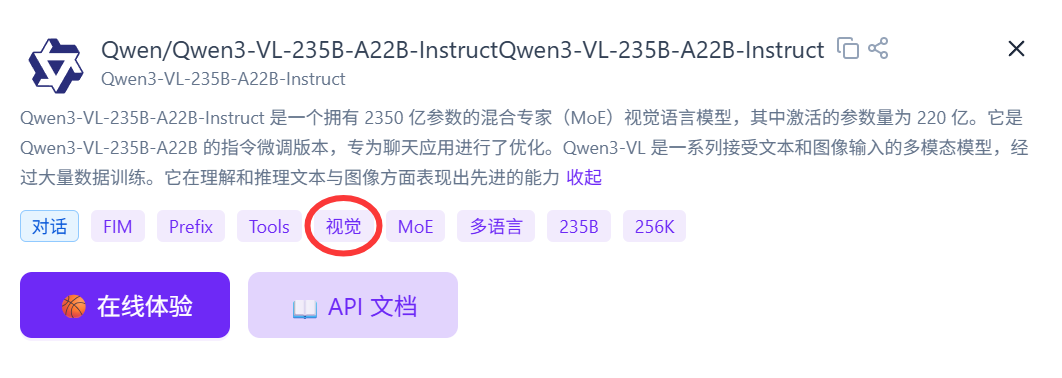
代表模型:Gemini3.0pro,claude4.5,Qwen3-VL-235B-A22B-Instruct
二者如何区分
根据名称进行区分:部分多模态模型的模型名称中会带有**“VL”**,例如Qwen3-VL-235B-A22B-Instruct
根据模型提供商的模型详情页进行区分:绝大多数模型供应商会在每个模型的详情页面中标注该模型支持哪些功能,若模型详情页中出现**“视觉”,“多模态”**等标签,则说明该模型为多模态模型,反之则为普通文本模型。
嵌入模型与重排序模型
注意:以下内容仅在使用漫画分析功能时需要了解。如果您只需要进行漫画翻译,可以跳过本节。
当某个模型的详情页面中,出现**“嵌入”,“embedding”标签时,则说明该模型为嵌入模型。当出现“重排序”**标签时,则说明该模型为重排序模型。关于二者的作用与详解,请继续看下文。
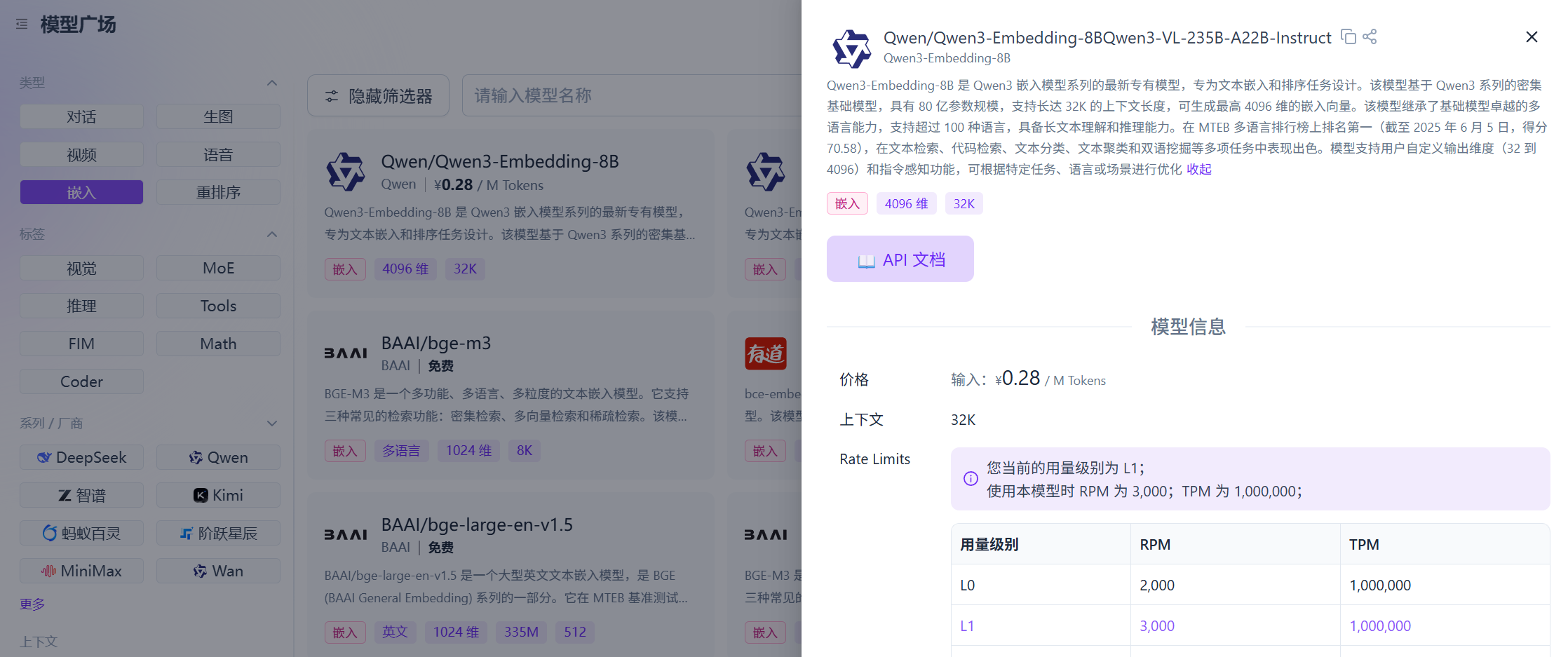
嵌入模型(Embedding Model)
什么是嵌入模型?
嵌入模型是一种将文本转换为高维向量的模型。简单来说,它可以将一段文字转化为一串数字,这串数字能够表示这段文字的语义含义。
在漫画分析中的作用
在 Saber Translator 的漫画分析功能中,嵌入模型用于:
- 构建知识库:将漫画的每一页内容转换为向量存储
- 语义检索:当你提问时,将问题转换为向量,然后在知识库中找到最相关的内容
- 上下文理解:帮助 AI 理解漫画的剧情连贯性和人物关系
- 突破上下文限制:借助RAG知识库机制,可无视模型的上下文限制进行智能问答,让从而智能问答功能适用于到任何篇幅的漫画。
若您没有配置嵌入模型,则将无法使用智能问答功能。
重排序模型(Reranker Model)
什么是重排序模型?
重排序模型是一种对检索结果进行二次排序的模型。它可以更精确地判断哪些内容与你的问题最相关。
在漫画分析中的作用
- 提高检索精度:嵌入模型检索出候选内容后,重排序模型会重新评分排序
- 减少噪音:过滤掉不太相关的内容,只保留最相关的部分
- 提升回答质量:确保 AI 基于最相关的上下文进行回答
工作流程
用户提问 → 嵌入模型检索(粗排)→ 重排序模型精排 → 最相关内容 → AI 生成回答常见问题
必须使用重排序模型吗?
不是必须的。重排序模型可以提高检索精度,但会增加成本和处理时间。对于简单的漫画分析,仅使用嵌入模型也能获得不错的效果。
嵌入模型和重排序模型可以混用吗?
可以。例如可以使用 OpenAI 的嵌入模型 + 本地的重排序模型,或者反过来。只要确保它们支持相同的语言即可。